AudioGenerationDiffusion
AUDIO GENERATION WITH DIFFUSION MODELS
This repository is maintained by Carlos Hernández-Oliván(carloshero@unizar.es) and it presents the State of the Art of Audio Generation with Diffusion models.
Make a pull request if you want to contribute to this references list.
All the images belong to their corresponding authors.
Table of Contents
1. Papers
2022
MM-Diffusion
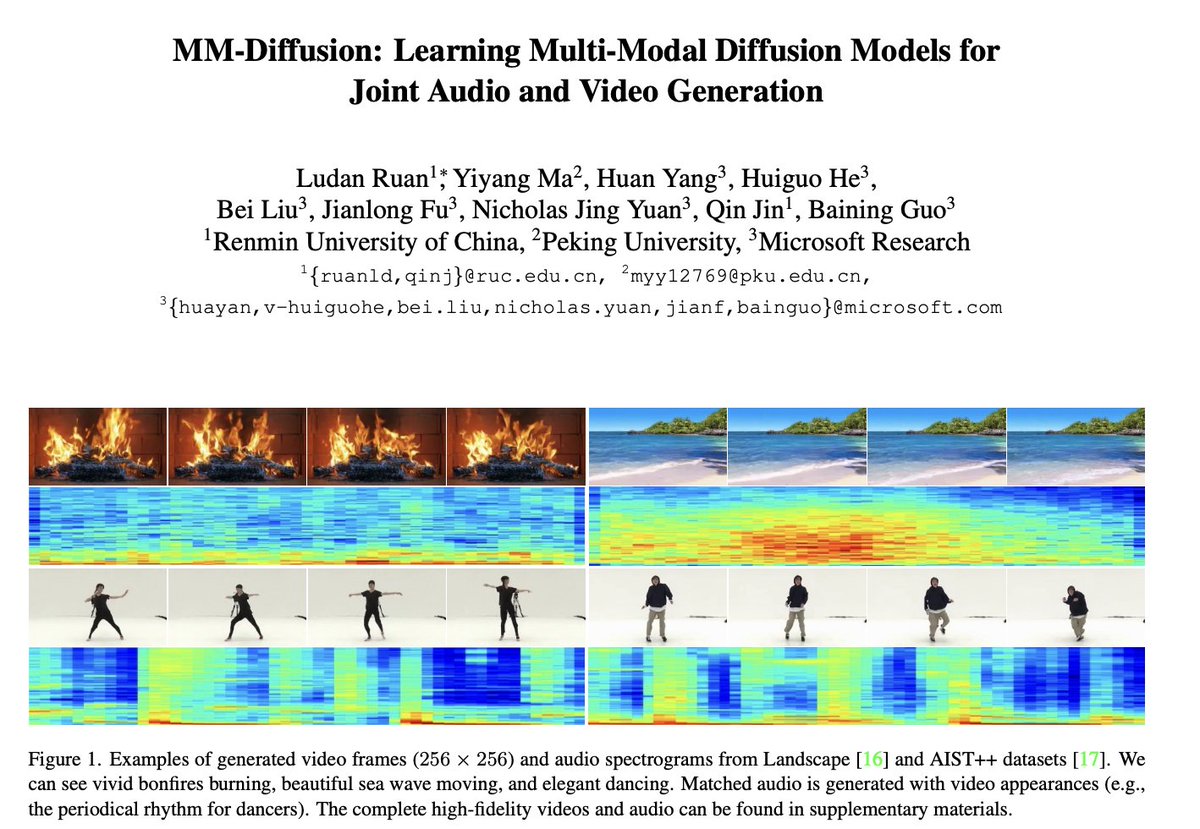
Ruan, Ludan and Ma, Yiyang and Yang, Huan and He, Huiguo and Liu, Bei and Fu, Jianlong and Yuan, Nicholas Jing and Jin, Qin and Guo, Baining. (2022). MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation.
2021
Diffwave (ICLR 2021)
Kong, Z., Ping, W., Huang, J., Zhao, K., & Catanzaro, B. (2020). Diffwave: A versatile diffusion model for audio synthesis. ICLR 2021.